
Printing Floating-Point Numbers - Part 2: Dragon4

The performance of what we write here will have a large impact on the overall algorithm. When I first got Dragon4 up and running, I was using a very C++ friendly public-domain big integer class that I found online. After everything was functional, I rewrote my own big integer code specifically tuned to the task at hand and performance increased over one hundred fold. That's not to say this is as optimized as possible, but it should be fast enough for production use.
This is the second part of a four part series. If you just want to hear about performance and download the code, skip ahead to part four.
License
All code samples are released under the following license.
/******************************************************************************
Copyright (c) 2014 Ryan Juckett
http://www.ryanjuckett.com/
This software is provided 'as-is', without any express or implied
warranty. In no event will the authors be held liable for any damages
arising from the use of this software.
Permission is granted to anyone to use this software for any purpose,
including commercial applications, and to alter it and redistribute it
freely, subject to the following restrictions:
1. The origin of this software must not be misrepresented; you must not
claim that you wrote the original software. If you use this software
in a product, an acknowledgment in the product documentation would be
appreciated but is not required.
2. Altered source versions must be plainly marked as such, and must not be
misrepresented as being the original software.
3. This notice may not be removed or altered from any source
distribution.
******************************************************************************/
Code Integration
In order to integrate this algorithm into your codebase, you'll need to define an assertion macro and typedefs for the standard types I use. Here is a simple example that should work with most modern compilers.
// Assertion macro
#define RJ_ASSERT(condition) assert(condition)
// Boolean types
typedef bool tB;
// Character types
typedef char tC8;
// Unsigned integer types
typedef uint8_t tU8;
typedef uint16_t tU16;
typedef uint32_t tU32;
typedef uint64_t tU64;
// Signed integer types
typedef int8_t tS8;
typedef int16_t tS16;
typedef int32_t tS32;
typedef int64_t tS64;
// Floating point types
typedef float tF32;
typedef double tF64;
// Size types
typedef size_t tSize;
typedef ptrdiff_t tPtrDiff;
Interface
This is the interface to the Dragon4 algorithm we are going to write. It can be used to convert an input floating-point number into a buffer of decimal digits and a power-of-ten exponent for the first digit. For example, the number 123.456 would produce the buffer { '1', '2', '3', '4', '5', '6' } and exponent 2. The caller needs to convert the floating-point input into a positive mantissa and exponent format prior to calling the function. In the next article, I'll show code to do just that and to format the output such that it is printable (e.g. "123.456" or "1.23456e+002").
//******************************************************************************
// Different modes for terminating digit output
//******************************************************************************
enum tCutoffMode
{
CutoffMode_Unique, // as many digits as necessary to print a uniquely identifiable number
CutoffMode_TotalLength, // up to cutoffNumber significant digits
CutoffMode_FractionLength, // up to cutoffNumber significant digits past the decimal point
};
//******************************************************************************
// This is an implementation the Dragon4 algorithm to convert a binary number
// in floating point format to a decimal number in string format. The function
// returns the number of digits written to the output buffer and the output is
// not NUL terminated.
//
// The floating point input value is (mantissa * 2^exponent).
//
// See the following papers for more information on the algorithm:
// "How to Print Floating-Point Numbers Accurately"
// Steele and White
// http://kurtstephens.com/files/p372-steele.pdf
// "Printing Floating-Point Numbers Quickly and Accurately"
// Burger and Dybvig
// http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.72.4656&rep=rep1&type=pdf
//******************************************************************************
tU32 Dragon4
(
tU64 mantissa, // value significand
tS32 exponent, // value exponent in base 2
tU32 mantissaHighBitIdx, // index of the highest set mantissa bit
tB hasUnequalMargins, // is the high margin twice as large as the low margin
tCutoffMode cutoffMode, // how to determine output length
tU32 cutoffNumber, // parameter to the selected cutoffMode
tC8 * pOutBuffer, // buffer to output into
tU32 bufferSize, // maximum characters that can be printed to pOutBuffer
tS32 * pOutExponent // the base 10 exponent of the first digit
);
Integer Math
When implementing Dragon4, we need a quick way to calculate the base-2 logarithm of an integer. We will also be using this function in the next part of this series when programming the formatting functions that wrap up Dragon4. The implementation is based on code from the bit twidling hacks website.
//******************************************************************************
// Get the log base 2 of a 32-bit unsigned integer.
// http://graphics.stanford.edu/~seander/bithacks.html#IntegerLogLookup
//******************************************************************************
tU32 LogBase2( tU32 val )
{
static const tU8 logTable[256] =
{
0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7
};
tU32 temp;
temp = val >> 24;
if (temp)
return 24 + logTable[temp];
temp = val >> 16;
if (temp)
return 16 + logTable[temp];
temp = val >> 8;
if (temp)
return 8 + logTable[temp];
return logTable[val];
}
Big Integer Type
This is the structure we will use to represent our big integers. It uses a statically sized array large enough to handle all the math needed by 64-bit floating-point values. This avoids any allocation costs from dynamic memory.
//******************************************************************************
// Maximum number of 32 bit blocks needed in high precision arithmetic
// to print out 64 bit IEEE floating point values.
//******************************************************************************
const tU32 c_BigInt_MaxBlocks = 35;
//******************************************************************************
// This structure stores a high precision unsigned integer. It uses a buffer
// of 32 bit integer blocks along with a length. The lowest bits of the integer
// are stored at the start of the buffer and the length is set to the minimum
// value that contains the integer. Thus, there are never any zero blocks at the
// end of the buffer.
//******************************************************************************
struct tBigInt
{
// Copy integer
tBigInt & operator=(const tBigInt &rhs)
{
tU32 length = rhs.m_length;
tU32 * pLhsCur = m_blocks;
for (const tU32 *pRhsCur = rhs.m_blocks, *pRhsEnd = pRhsCur + length;
pRhsCur != pRhsEnd;
++pLhsCur, ++pRhsCur)
{
*pLhsCur = *pRhsCur;
}
m_length = length;
return *this;
}
// Data accessors
tU32 GetLength() const { return m_length; }
tU32 GetBlock(tU32 idx) const { return m_blocks[idx]; }
// Zero helper functions
void SetZero() { m_length = 0; }
tB IsZero() const { return m_length == 0; }
// Basic type accessors
void SetU64(tU64 val)
{
if (val > 0xFFFFFFFF)
{
m_blocks[0] = val & 0xFFFFFFFF;
m_blocks[1] = (val >> 32) & 0xFFFFFFFF;
m_length = 2;
}
else if (val != 0)
{
m_blocks[0] = val & 0xFFFFFFFF;
m_length = 1;
}
else
{
m_length = 0;
}
}
void SetU32(tU32 val)
{
if (val != 0)
{
m_blocks[0] = val;
m_length = (val != 0);
}
else
{
m_length = 0;
}
}
tU32 GetU32() const { return (m_length == 0) ? 0 : m_blocks[0]; }
// Member data
tU32 m_length;
tU32 m_blocks[c_BigInt_MaxBlocks];
};
Big Integer Comparison
The comparison function works similar to strcmp and can be used to test any combination of equality, greater than or less than.
//******************************************************************************
// Returns 0 if (lhs = rhs), negative if (lhs < rhs), positive if (lhs > rhs)
//******************************************************************************
static tS32 BigInt_Compare(const tBigInt & lhs, const tBigInt & rhs)
{
// A bigger length implies a bigger number.
tS32 lengthDiff = lhs.m_length - rhs.m_length;
if (lengthDiff != 0)
return lengthDiff;
// Compare blocks one by one from high to low.
for (tS32 i = lhs.m_length - 1; i >= 0; --i)
{
if (lhs.m_blocks[i] == rhs.m_blocks[i])
continue;
else if (lhs.m_blocks[i] > rhs.m_blocks[i])
return 1;
else
return -1;
}
// no blocks differed
return 0;
}
Big Integer Addition
The addition implementation is a rather straight forward long-addition algorithm with the carry tracked in a 64-bit integer. The only real point of interest is that the inputs are allowed to alias the same value (i.e. even though parameters are passed by reference, it does not matter if they all point to the same memory).
//******************************************************************************
// result = lhs + rhs
//******************************************************************************
static void BigInt_Add(tBigInt * pResult, const tBigInt & lhs, const tBigInt & rhs)
{
// determine which operand has the smaller length
const tBigInt * pLarge;
const tBigInt * pSmall;
if (lhs.m_length < rhs.m_length)
{
pSmall = &lhs;
pLarge = &rhs;
}
else
{
pSmall = &rhs;
pLarge = &lhs;
}
const tU32 largeLen = pLarge->m_length;
const tU32 smallLen = pSmall->m_length;
// The output will be at least as long as the largest input
pResult->m_length = largeLen;
// Add each block and add carry the overflow to the next block
tU64 carry = 0;
const tU32 * pLargeCur = pLarge->m_blocks;
const tU32 * pLargeEnd = pLargeCur + largeLen;
const tU32 * pSmallCur = pSmall->m_blocks;
const tU32 * pSmallEnd = pSmallCur + smallLen;
tU32 * pResultCur = pResult->m_blocks;
while (pSmallCur != pSmallEnd)
{
tU64 sum = carry + (tU64)(*pLargeCur) + (tU64)(*pSmallCur);
carry = sum >> 32;
(*pResultCur) = sum & 0xFFFFFFFF;
++pLargeCur;
++pSmallCur;
++pResultCur;
}
// Add the carry to any blocks that only exist in the large operand
while (pLargeCur != pLargeEnd)
{
tU64 sum = carry + (tU64)(*pLargeCur);
carry = sum >> 32;
(*pResultCur) = sum & 0xFFFFFFFF;
++pLargeCur;
++pResultCur;
}
// If there's still a carry, append a new block
if (carry != 0)
{
RJ_ASSERT(carry == 1);
RJ_ASSERT((tU32)(pResultCur - pResult->m_blocks) == largeLen && (largeLen < c_BigInt_MaxBlocks));
*pResultCur = 1;
pResult->m_length = largeLen + 1;
}
else
{
pResult->m_length = largeLen;
}
}
Big Integer Multiplication
For multiplication, we start with the generalized long-multiplication of two high precision integers. We then implement a set of optimized implementations for specific use cases where an operand is of a small size or is a constant number.
//******************************************************************************
// result = lhs * rhs
//******************************************************************************
static void BigInt_Multiply(tBigInt * pResult, const tBigInt &lhs, const tBigInt &rhs)
{
RJ_ASSERT( pResult != &lhs && pResult != &rhs );
// determine which operand has the smaller length
const tBigInt * pLarge;
const tBigInt * pSmall;
if (lhs.m_length < rhs.m_length)
{
pSmall = &lhs;
pLarge = &rhs;
}
else
{
pSmall = &rhs;
pLarge = &lhs;
}
// set the maximum possible result length
tU32 maxResultLen = pLarge->m_length + pSmall->m_length;
RJ_ASSERT( maxResultLen <= c_BigInt_MaxBlocks );
// clear the result data
for(tU32 * pCur = pResult->m_blocks, *pEnd = pCur + maxResultLen; pCur != pEnd; ++pCur)
*pCur = 0;
// perform standard long multiplication
const tU32 *pLargeBeg = pLarge->m_blocks;
const tU32 *pLargeEnd = pLargeBeg + pLarge->m_length;
// for each small block
tU32 *pResultStart = pResult->m_blocks;
for(const tU32 *pSmallCur = pSmall->m_blocks, *pSmallEnd = pSmallCur + pSmall->m_length;
pSmallCur != pSmallEnd;
++pSmallCur, ++pResultStart)
{
// if non-zero, multiply against all the large blocks and add into the result
const tU32 multiplier = *pSmallCur;
if (multiplier != 0)
{
const tU32 *pLargeCur = pLargeBeg;
tU32 *pResultCur = pResultStart;
tU64 carry = 0;
do
{
tU64 product = (*pResultCur) + (*pLargeCur)*(tU64)multiplier + carry;
carry = product >> 32;
*pResultCur = product & 0xFFFFFFFF;
++pLargeCur;
++pResultCur;
} while(pLargeCur != pLargeEnd);
RJ_ASSERT(pResultCur < pResult->m_blocks + maxResultLen);
*pResultCur = (tU32)(carry & 0xFFFFFFFF);
}
}
// check if the terminating block has no set bits
if (maxResultLen > 0 && pResult->m_blocks[maxResultLen - 1] == 0)
pResult->m_length = maxResultLen-1;
else
pResult->m_length = maxResultLen;
}
//******************************************************************************
// result = lhs * rhs
//******************************************************************************
static void BigInt_Multiply(tBigInt * pResult, const tBigInt & lhs, tU32 rhs)
{
// perform long multiplication
tU32 carry = 0;
tU32 *pResultCur = pResult->m_blocks;
const tU32 *pLhsCur = lhs.m_blocks;
const tU32 *pLhsEnd = lhs.m_blocks + lhs.m_length;
for ( ; pLhsCur != pLhsEnd; ++pLhsCur, ++pResultCur )
{
tU64 product = (tU64)(*pLhsCur) * rhs + carry;
*pResultCur = (tU32)(product & 0xFFFFFFFF);
carry = product >> 32;
}
// if there is a remaining carry, grow the array
if (carry != 0)
{
// grow the array
RJ_ASSERT(lhs.m_length + 1 <= c_BigInt_MaxBlocks);
*pResultCur = (tU32)carry;
pResult->m_length = lhs.m_length + 1;
}
else
{
pResult->m_length = lhs.m_length;
}
}
//******************************************************************************
// result = in * 2
//******************************************************************************
static void BigInt_Multiply2(tBigInt * pResult, const tBigInt &in)
{
// shift all the blocks by one
tU32 carry = 0;
tU32 *pResultCur = pResult->m_blocks;
const tU32 *pLhsCur = in.m_blocks;
const tU32 *pLhsEnd = in.m_blocks + in.m_length;
for ( ; pLhsCur != pLhsEnd; ++pLhsCur, ++pResultCur )
{
tU32 cur = *pLhsCur;
*pResultCur = (cur << 1) | carry;
carry = cur >> 31;
}
if (carry != 0)
{
// grow the array
RJ_ASSERT(in.m_length + 1 <= c_BigInt_MaxBlocks);
*pResultCur = carry;
pResult->m_length = in.m_length + 1;
}
else
{
pResult->m_length = in.m_length;
}
}
//******************************************************************************
// result = result * 2
//******************************************************************************
static void BigInt_Multiply2(tBigInt * pResult)
{
// shift all the blocks by one
tU32 carry = 0;
tU32 *pCur = pResult->m_blocks;
tU32 *pEnd = pResult->m_blocks + pResult->m_length;
for ( ; pCur != pEnd; ++pCur )
{
tU32 cur = *pCur;
*pCur = (cur << 1) | carry;
carry = cur >> 31;
}
if (carry != 0)
{
// grow the array
RJ_ASSERT(pResult->m_length + 1 <= c_BigInt_MaxBlocks);
*pCur = carry;
++pResult->m_length;
}
}
//******************************************************************************
// result = result * 10
//******************************************************************************
static void BigInt_Multiply10(tBigInt * pResult)
{
// multiply all the blocks
tU64 carry = 0;
tU32 *pCur = pResult->m_blocks;
tU32 *pEnd = pResult->m_blocks + pResult->m_length;
for ( ; pCur != pEnd; ++pCur )
{
tU64 product = (tU64)(*pCur) * 10ull + carry;
(*pCur) = (tU32)(product & 0xFFFFFFFF);
carry = product >> 32;
}
if (carry != 0)
{
// grow the array
RJ_ASSERT(pResult->m_length + 1 <= c_BigInt_MaxBlocks);
*pCur = (tU32)carry;
++pResult->m_length;
}
}
Big Integer Exponentiation
We will be evaluating exponents with bases of 2 and 10. Raising 2 to a power is achievable with a simple bit shift, leaving raising 10 to a power as the only complicated case. We employ a set of lookup tables to improve performance. Rather than creating a giant lookup table that contains data for every possible exponent, we can instead split the exponent into powers of 2 creating a small table. Consider the case of evaluating \(10^{234}\). The number \(234\) can be broken down as \((128 + 64 + 32 + 8)\) which is equivalent to \((2^7 + 2^6 + 2^5 + 2^3)\). We can now rewrite \(10^{234}\) as \(\Large{10^{2^7} * 10^{2^6} * 10^{2^5} * 10^{2^3}}\). By making a lookup table for \(\Large{10^{2^x}}\), we can evaluate table[7] * table[6] * table[5] * table[3] to compute the result.
We take this one step farther by storing powers zero through eight in a table of small integers. This avoids numerous small multiplications at little cost.
In addition to often raising 10 to a power, we also multiply numbers by 10 raised to a power. The second function below is optimized to perform the multiplication along with the exponentiation.
//******************************************************************************
//******************************************************************************
static tU32 g_PowerOf10_U32[] =
{
1, // 10 ^ 0
10, // 10 ^ 1
100, // 10 ^ 2
1000, // 10 ^ 3
10000, // 10 ^ 4
100000, // 10 ^ 5
1000000, // 10 ^ 6
10000000, // 10 ^ 7
};
//******************************************************************************
// Note: This has a lot of wasted space in the big integer structures of the
// early table entries. It wouldn't be terribly hard to make the multiply
// function work on integer pointers with an array length instead of
// the tBigInt struct which would allow us to store a minimal amount of
// data here.
//******************************************************************************
static tBigInt g_PowerOf10_Big[] =
{
// 10 ^ 8
{ 1, { 100000000 } },
// 10 ^ 16
{ 2, { 0x6fc10000, 0x002386f2 } },
// 10 ^ 32
{ 4, { 0x00000000, 0x85acef81, 0x2d6d415b, 0x000004ee, } },
// 10 ^ 64
{ 7, { 0x00000000, 0x00000000, 0xbf6a1f01, 0x6e38ed64, 0xdaa797ed, 0xe93ff9f4, 0x00184f03, } },
// 10 ^ 128
{ 14, { 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x2e953e01, 0x03df9909, 0x0f1538fd,
0x2374e42f, 0xd3cff5ec, 0xc404dc08, 0xbccdb0da, 0xa6337f19, 0xe91f2603, 0x0000024e, } },
// 10 ^ 256
{ 27, { 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000,
0x00000000, 0x982e7c01, 0xbed3875b, 0xd8d99f72, 0x12152f87, 0x6bde50c6, 0xcf4a6e70,
0xd595d80f, 0x26b2716e, 0xadc666b0, 0x1d153624, 0x3c42d35a, 0x63ff540e, 0xcc5573c0,
0x65f9ef17, 0x55bc28f2, 0x80dcc7f7, 0xf46eeddc, 0x5fdcefce, 0x000553f7, } }
};
//******************************************************************************
// result = 10^exponent
//******************************************************************************
static void BigInt_Pow10(tBigInt * pResult, tU32 exponent)
{
// make sure the exponenet is within the bounds of the lookup table data
RJ_ASSERT(exponent < 512);
// create two temporary values to reduce large integer copy operations
tBigInt temp1;
tBigInt temp2;
tBigInt *pCurTemp = &temp1;
tBigInt *pNextTemp = &temp2;
// initialize the result by looking up a 32-bit power of 10 corresponding to the first 3 bits
tU32 smallExponent = exponent & 0x7;
pCurTemp->SetU32(g_PowerOf10_U32[smallExponent]);
// remove the low bits that we used for the 32-bit lookup table
exponent >>= 3;
tU32 tableIdx = 0;
// while there are remaining bits in the exponent to be processed
while (exponent != 0)
{
// if the current bit is set, multiply it with the corresponding power of 10
if(exponent & 1)
{
// multiply into the next temporary
BigInt_Multiply( pNextTemp, *pCurTemp, g_PowerOf10_Big[tableIdx] );
// swap to the next temporary
tBigInt * pSwap = pCurTemp;
pCurTemp = pNextTemp;
pNextTemp = pSwap;
}
// advance to the next bit
++tableIdx;
exponent >>= 1;
}
// output the result
*pResult = *pCurTemp;
}
//******************************************************************************
// result = in * 10^exponent
//******************************************************************************
static void BigInt_MultiplyPow10(tBigInt * pResult, const tBigInt & in, tU32 exponent)
{
// make sure the exponent is within the bounds of the lookup table data
RJ_ASSERT(exponent < 512);
// create two temporary values to reduce large integer copy operations
tBigInt temp1;
tBigInt temp2;
tBigInt *pCurTemp = &temp1;
tBigInt *pNextTemp = &temp2;
// initialize the result by looking up a 32-bit power of 10 corresponding to the first 3 bits
tU32 smallExponent = exponent & 0x7;
if (smallExponent != 0)
{
BigInt_Multiply( pCurTemp, in, g_PowerOf10_U32[smallExponent] );
}
else
{
*pCurTemp = in;
}
// remove the low bits that we used for the 32-bit lookup table
exponent >>= 3;
tU32 tableIdx = 0;
// while there are remaining bits in the exponent to be processed
while (exponent != 0)
{
// if the current bit is set, multiply it with the corresponding power of 10
if(exponent & 1)
{
// multiply into the next temporary
BigInt_Multiply( pNextTemp, *pCurTemp, g_PowerOf10_Big[tableIdx] );
// swap to the next temporary
tBigInt * pSwap = pCurTemp;
pCurTemp = pNextTemp;
pNextTemp = pSwap;
}
// advance to the next bit
++tableIdx;
exponent >>= 1;
}
// output the result
*pResult = *pCurTemp;
}
//******************************************************************************
// result = 2^exponent
//******************************************************************************
static inline void BigInt_Pow2(tBigInt * pResult, tU32 exponent)
{
tU32 blockIdx = exponent / 32;
RJ_ASSERT( blockIdx < c_BigInt_MaxBlocks );
for ( tU32 i = 0; i <= blockIdx; ++i)
pResult->m_blocks[i] = 0;
pResult->m_length = blockIdx + 1;
tU32 bitIdx = (exponent % 32);
pResult->m_blocks[blockIdx] |= (1 << bitIdx);
}
Big Integer Division
A common operation in the digit printing algorithm is a division to find the current digit followed by setting the value to the remainder. We can take advantage of this knowledge in two ways. The most straightforward is to compute the remainder as part of the division algorithm. The second is to optimize around our resulting quotient (represented as an integer with the remainder output separately) always being in the range [0,9].
I tried a few different approaches to the division algorithm because it ends up being one of the slowest parts in the process. Prior to settling on this version, I had promising results exploiting how the divisions are performed in a loop where the denominator never changes. I precomputed different multiples of the denominator up front and compared against them to quickly partition the possible results. Essentially, I did a binary search in the range [0,9] for the result.
What ended up being faster was computing a quick approximation of the quotient that is guaranteed to be equal to or one less than the correct value. From that point, we check for accuracy and adjust the results if the estimate was wrong.
The approximation is based on the following statements:
- Let \(A \geq 0\) and \(B > 0\). We can guarantee that \(\Large{\lfloor\frac{valueNumerator} {valueDenominator}\rfloor \geq \lfloor\frac{valueNumerator - A} {valueDenominator + B}\rfloor}\)
- If we set all 32-bit blocks of the value numerator to zero except for the highest one, we end up with a number that is less than or equal to the numerator.
- If the highest 32-bit block of the value denominator is less than 0xFFFFFFFF and we increment it by one while setting all following blocks to zero, we end up with a number that is greater than the denominator.
Assume that the integer-based numerator and denominator both have the same number of 32-bit integer blocks, \(n\). We can shift the decimal point to line up with the highest block by letting \(\Large{a = \frac {valueNumerator} {2^{32*(n-1)}}}\) and \(\Large{b = \frac {valueDenominator} {2^{32*(n-1)}}}\). We can now define the high block of the numerator and denominator as \(\lfloor a \rfloor\) and \(\lfloor b \rfloor\) respectively.
The exact quotient is \(\frac{a} {b}\) and according to statement 1 above, we can create a quick approximation of by computing \(\lfloor\frac{\lfloor a \rfloor} {\lfloor b \rfloor + 1}\rfloor\). The approximation is guaranteed to be less than the actual quotient. It is also equivalent to the integer division of the highest numerator block by one plus the highest denominator block. This is a good start, but the approximation isn't accurate enough to be very useful. To get an estimate that has a bounded error of (-2,0], we can create the following constraint on \(a\) and \(b\):
\( \frac{a} {b}- \lfloor\frac{\lfloor a \rfloor} {\lfloor b \rfloor + 1 }\rfloor < 2 \)
The higher \(b\) gets, the lower the error gets because we have more precision in the high block. If we can find a minimum value for \(b\) that satisfies the constraint for all values of \(a\) (recall that \(a\) is always less than 10 times the size of \(b\)), all higher values of \(b\) will also satisfy the constraint.
I'd love to use equations and inequalities to elegantly solve for the minimum \(b\), but it turns out that systems of equations containing multiple variables and floor functions are outside the bounds of my math education. Thus, we are going to settle on empirical data instead of a proper proof. In this 3D graph, we can see the following equations:
- \(error = \frac{a} {b}- \lfloor\frac{\lfloor a \rfloor} {\lfloor b \rfloor + 1 }\rfloor\)
- This is the interesting spiked surface (you might even say it looks like dragon scales). It represents the error between our approximate quotient and the actual quotient.
- \(error = 2\)
- This is the horizontal plane intersecting the error function. Anywhere the error pokes up through this plane is too inaccurate and will not satisfy our constraint.
- \(a = 10 b\)
- This is the vertical wall cutting the graph at a diagonal. It separates the legal combinations of \(a\) and \(b\) (below the wall) from the illegal combinations (on and above the wall).
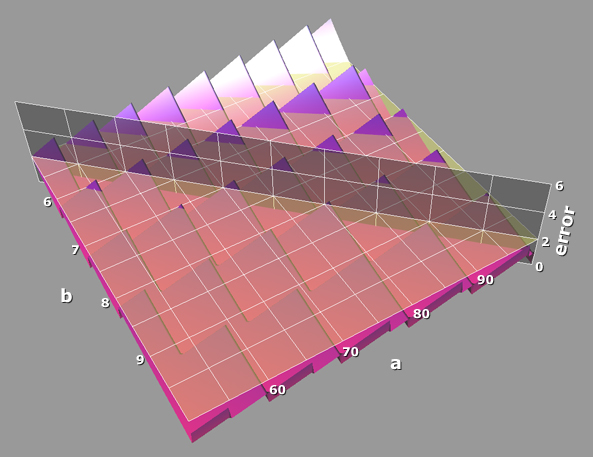
Inspecting the graph, we can see that when \(8 \leq b \lt 9\), the error stays within range all the way up to the \(a = 10 b\) wall. When \(b\) is eight, the error pokes above the acceptable range exactly at the wall boundary (i.e when \(a = 80\)). From this, we can guarantee that if the highest 32-bit integer block of our denominator is greater than or equal to eight, we can approximate the quotient within an error of one using a single integer division. We require the caller to satisfy this constraint by scaling up the numerator and denominator appropriately prior to calling this function.
We still have a couple kinks to deal with. The dividend and divisor need to have the same length and the highest block of the divisor must be less than the maximum value of an unsigned 32-bit integer such that it is safe to increment when generating our estimate quotient. Because the numerator and denominator are within a scale of ten from one another, these conditions always be satisfied by scaling the input. Once again, the caller is responsible for scaling up the numerator and denominator accordingly until they are valid.
//******************************************************************************
// This function will divide two large numbers under the assumption that the
// result is within the range [0,10) and the input numbers have been shifted
// to satisfy:
// - The highest block of the divisor is greater than or equal to 8 such that
// there is enough precision to make an accurate first guess at the quotient.
// - The highest block of the divisor is less than the maximum value on an
// unsigned 32-bit integer such that we can safely increment without overflow.
// - The dividend does not contain more blocks than the divisor such that we
// can estimate the quotient by dividing the equivalently placed high blocks.
//
// quotient = floor(dividend / divisor)
// remainder = dividend - quotient*divisor
//
// pDividend is updated to be the remainder and the quotient is returned.
//******************************************************************************
static tU32 BigInt_DivideWithRemainder_MaxQuotient9(tBigInt * pDividend, const tBigInt & divisor)
{
// Check that the divisor has been correctly shifted into range and that it is not
// smaller than the dividend in length.
RJ_ASSERT( !divisor.IsZero() &&
divisor.m_blocks[divisor.m_length-1] >= 8 &&
divisor.m_blocks[divisor.m_length-1] < 0xFFFFFFFF &&
pDividend->m_length <= divisor.m_length );
// If the dividend is smaller than the divisor, the quotient is zero and the divisor is already
// the remainder.
tU32 length = divisor.m_length;
if (pDividend->m_length < divisor.m_length)
return 0;
const tU32 * pFinalDivisorBlock = divisor.m_blocks + length - 1;
tU32 * pFinalDividendBlock = pDividend->m_blocks + length - 1;
// Compute an estimated quotient based on the high block value. This will either match the actual quotient or
// undershoot by one.
tU32 quotient = *pFinalDividendBlock / (*pFinalDivisorBlock + 1);
RJ_ASSERT(quotient <= 9);
// Divide out the estimated quotient
if (quotient != 0)
{
// dividend = dividend - divisor*quotient
const tU32 *pDivisorCur = divisor.m_blocks;
tU32 *pDividendCur = pDividend->m_blocks;
tU64 borrow = 0;
tU64 carry = 0;
do
{
tU64 product = (tU64)*pDivisorCur * (tU64)quotient + carry;
carry = product >> 32;
tU64 difference = (tU64)*pDividendCur - (product & 0xFFFFFFFF) - borrow;
borrow = (difference >> 32) & 1;
*pDividendCur = difference & 0xFFFFFFFF;
++pDivisorCur;
++pDividendCur;
} while(pDivisorCur <= pFinalDivisorBlock);
// remove all leading zero blocks from dividend
while (length > 0 && pDividend->m_blocks[length - 1] == 0)
--length;
pDividend->m_length = length;
}
// If the dividend is still larger than the divisor, we overshot our estimate quotient. To correct,
// we increment the quotient and subtract one more divisor from the dividend.
if ( BigInt_Compare(*pDividend, divisor) >= 0 )
{
++quotient;
// dividend = dividend - divisor
const tU32 *pDivisorCur = divisor.m_blocks;
tU32 *pDividendCur = pDividend->m_blocks;
tU64 borrow = 0;
do
{
tU64 difference = (tU64)*pDividendCur - (tU64)*pDivisorCur - borrow;
borrow = (difference >> 32) & 1;
*pDividendCur = difference & 0xFFFFFFFF;
++pDivisorCur;
++pDividendCur;
} while(pDivisorCur <= pFinalDivisorBlock);
// remove all leading zero blocks from dividend
while (length > 0 && pDividend->m_blocks[length - 1] == 0)
--length;
pDividend->m_length = length;
}
return quotient;
}
Big Integer Shift
The shift-left implementation is a straight forward in-place shift. If the shift length is a multiple of the bits per block, it takes an optimized branch for shifting one full block at a time.
//******************************************************************************
// result = result << shift
//******************************************************************************
static void BigInt_ShiftLeft(tBigInt * pResult, tU32 shift)
{
RJ_ASSERT( shift != 0 );
tU32 shiftBlocks = shift / 32;
tU32 shiftBits = shift % 32;
// process blocks high to low so that we can safely process in place
const tU32 * pInBlocks = pResult->m_blocks;
tS32 inLength = pResult->m_length;
RJ_ASSERT( inLength + shiftBlocks <= c_BigInt_MaxBlocks );
// check if the shift is block aligned
if (shiftBits == 0)
{
// copy blocks from high to low
for (tU32 * pInCur = pResult->m_blocks + inLength - 1, *pOutCur = pInCur + shiftBlocks;
pInCur >= pInBlocks;
--pInCur, --pOutCur)
{
*pOutCur = *pInCur;
}
// zero the remaining low blocks
for ( tU32 i = 0; i < shiftBlocks; ++i)
pResult->m_blocks[i] = 0;
pResult->m_length += shiftBlocks;
}
// else we need to shift partial blocks
else
{
tS32 inBlockIdx = inLength - 1;
tU32 outBlockIdx = inLength + shiftBlocks;
// set the length to hold the shifted blocks
RJ_ASSERT( outBlockIdx < c_BigInt_MaxBlocks );
pResult->m_length = outBlockIdx + 1;
// output the initial blocks
const tU32 lowBitsShift = (32 - shiftBits);
tU32 highBits = 0;
tU32 block = pResult->m_blocks[inBlockIdx];
tU32 lowBits = block >> lowBitsShift;
while ( inBlockIdx > 0 )
{
pResult->m_blocks[outBlockIdx] = highBits | lowBits;
highBits = block << shiftBits;
--inBlockIdx;
--outBlockIdx;
block = pResult->m_blocks[inBlockIdx];
lowBits = block >> lowBitsShift;
}
// output the final blocks
RJ_ASSERT( outBlockIdx == shiftBlocks + 1 );
pResult->m_blocks[outBlockIdx] = highBits | lowBits;
pResult->m_blocks[outBlockIdx-1] = block << shiftBits;
// zero the remaining low blocks
for ( tU32 i = 0; i < shiftBlocks; ++i)
pResult->m_blocks[i] = 0;
// check if the terminating block has no set bits
if (pResult->m_blocks[pResult->m_length - 1] == 0)
--pResult->m_length;
}
}
Dragon4
Finally, we get to the actual Dragon4 algorithm. Outside of optimizations to reduce math operations, the main differences between this and the original paper are support for a limited output buffer size and proper rounding up of the final digit when it is a 9. You'll also notice that the length-based cutoff modes use an optimized digit loop that does not care about margin values. At the cost of more code, this split could happen even earlier and prevent all margin related computations.
//******************************************************************************
// This is an implementation the Dragon4 algorithm to convert a binary number
// in floating point format to a decimal number in string format. The function
// returns the number of digits written to the output buffer and the output is
// not NUL terminated.
//
// The floating point input value is (mantissa * 2^exponent).
//
// See the following papers for more information on the algorithm:
// "How to Print Floating-Point Numbers Accurately"
// Steele and White
// http://kurtstephens.com/files/p372-steele.pdf
// "Printing Floating-Point Numbers Quickly and Accurately"
// Burger and Dybvig
// http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.72.4656&rep=rep1&type=pdf
//******************************************************************************
tU32 Dragon4
(
const tU64 mantissa, // value significand
const tS32 exponent, // value exponent in base 2
const tU32 mantissaHighBitIdx, // index of the highest set mantissa bit
const tB hasUnequalMargins, // is the high margin twice as large as the low margin
const tCutoffMode cutoffMode, // how to determine output length
tU32 cutoffNumber, // parameter to the selected cutoffMode
tC8 * pOutBuffer, // buffer to output into
tU32 bufferSize, // maximum characters that can be printed to pOutBuffer
tS32 * pOutExponent // the base 10 exponent of the first digit
)
{
tC8 * pCurDigit = pOutBuffer;
RJ_ASSERT( bufferSize > 0 );
// if the mantissa is zero, the value is zero regardless of the exponent
if (mantissa == 0)
{
*pCurDigit = '0';
*pOutExponent = 0;
return 1;
}
// compute the initial state in integral form such that
// value = scaledValue / scale
// marginLow = scaledMarginLow / scale
tBigInt scale; // positive scale applied to value and margin such that they can be
// represented as whole numbers
tBigInt scaledValue; // scale * mantissa
tBigInt scaledMarginLow; // scale * 0.5 * (distance between this floating-point number and its
// immediate lower value)
// For normalized IEEE floating point values, each time the exponent is incremented the margin also
// doubles. That creates a subset of transition numbers where the high margin is twice the size of
// the low margin.
tBigInt * pScaledMarginHigh;
tBigInt optionalMarginHigh;
if ( hasUnequalMargins )
{
// if we have no fractional component
if (exponent > 0)
{
// 1) Expand the input value by multiplying out the mantissa and exponent. This represents
// the input value in its whole number representation.
// 2) Apply an additional scale of 2 such that later comparisons against the margin values
// are simplified.
// 3) Set the margin value to the lowest mantissa bit's scale.
// scaledValue = 2 * 2 * mantissa*2^exponent
scaledValue.SetU64( 4 * mantissa );
BigInt_ShiftLeft( &scaledValue, exponent );
// scale = 2 * 2 * 1
scale.SetU32( 4 );
// scaledMarginLow = 2 * 2^(exponent-1)
BigInt_Pow2( &scaledMarginLow, exponent );
// scaledMarginHigh = 2 * 2 * 2^(exponent-1)
BigInt_Pow2( &optionalMarginHigh, exponent + 1 );
}
// else we have a fractional exponent
else
{
// In order to track the mantissa data as an integer, we store it as is with a large scale
// scaledValue = 2 * 2 * mantissa
scaledValue.SetU64( 4 * mantissa );
// scale = 2 * 2 * 2^(-exponent)
BigInt_Pow2(&scale, -exponent + 2 );
// scaledMarginLow = 2 * 2^(-1)
scaledMarginLow.SetU32( 1 );
// scaledMarginHigh = 2 * 2 * 2^(-1)
optionalMarginHigh.SetU32( 2 );
}
// the high and low margins are different
pScaledMarginHigh = &optionalMarginHigh;
}
else
{
// if we have no fractional component
if (exponent > 0)
{
// 1) Expand the input value by multiplying out the mantissa and exponent. This represents
// the input value in its whole number representation.
// 2) Apply an additional scale of 2 such that later comparisons against the margin values
// are simplified.
// 3) Set the margin value to the lowest mantissa bit's scale.
// scaledValue = 2 * mantissa*2^exponent
scaledValue.SetU64( 2 * mantissa );
BigInt_ShiftLeft( &scaledValue, exponent );
// scale = 2 * 1
scale.SetU32( 2 );
// scaledMarginLow = 2 * 2^(exponent-1)
BigInt_Pow2( &scaledMarginLow, exponent );
}
// else we have a fractional exponent
else
{
// In order to track the mantissa data as an integer, we store it as is with a large scale
// scaledValue = 2 * mantissa
scaledValue.SetU64( 2 * mantissa );
// scale = 2 * 2^(-exponent)
BigInt_Pow2(&scale, -exponent + 1 );
// scaledMarginLow = 2 * 2^(-1)
scaledMarginLow.SetU32( 1 );
}
// the high and low margins are equal
pScaledMarginHigh = &scaledMarginLow;
}
// Compute an estimate for digitExponent that will be correct or undershoot by one.
// This optimization is based on the paper "Printing Floating-Point Numbers Quickly and Accurately"
// by Burger and Dybvig http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.72.4656&rep=rep1&type=pdf
// We perform an additional subtraction of 0.69 to increase the frequency of a failed estimate
// because that lets us take a faster branch in the code. 0.69 is chosen because 0.69 + log10(2) is
// less than one by a reasonable epsilon that will account for any floating point error.
//
// We want to set digitExponent to floor(log10(v)) + 1
// v = mantissa*2^exponent
// log2(v) = log2(mantissa) + exponent;
// log10(v) = log2(v) * log10(2)
// floor(log2(v)) = mantissaHighBitIdx + exponent;
// log10(v) - log10(2) < (mantissaHighBitIdx + exponent) * log10(2) <= log10(v)
// log10(v) < (mantissaHighBitIdx + exponent) * log10(2) + log10(2) <= log10(v) + log10(2)
// floor( log10(v) ) < ceil( (mantissaHighBitIdx + exponent) * log10(2) ) <= floor( log10(v) ) + 1
const tF64 log10_2 = 0.30102999566398119521373889472449;
tS32 digitExponent = (tS32)(ceil(tF64((tS32)mantissaHighBitIdx + exponent) * log10_2 - 0.69));
// if the digit exponent is smaller than the smallest desired digit for fractional cutoff,
// pull the digit back into legal range at which point we will round to the appropriate value.
// Note that while our value for digitExponent is still an estimate, this is safe because it
// only increases the number. This will either correct digitExponent to an accurate value or it
// will clamp it above the accurate value.
if (cutoffMode == CutoffMode_FractionLength && digitExponent <= -(tS32)cutoffNumber)
{
digitExponent = -(tS32)cutoffNumber + 1;
}
// Divide value by 10^digitExponent.
if (digitExponent > 0)
{
// The exponent is positive creating a division so we multiply up the scale.
tBigInt temp;
BigInt_MultiplyPow10( &temp, scale, digitExponent );
scale = temp;
}
else if (digitExponent < 0)
{
// The exponent is negative creating a multiplication so we multiply up the scaledValue,
// scaledMarginLow and scaledMarginHigh.
tBigInt pow10;
BigInt_Pow10( &pow10, -digitExponent);
tBigInt temp;
BigInt_Multiply( &temp, scaledValue, pow10);
scaledValue = temp;
BigInt_Multiply( &temp, scaledMarginLow, pow10);
scaledMarginLow = temp;
if (pScaledMarginHigh != &scaledMarginLow)
BigInt_Multiply2( pScaledMarginHigh, scaledMarginLow );
}
// If (value >= 1), our estimate for digitExponent was too low
if( BigInt_Compare(scaledValue,scale) >= 0 )
{
// The exponent estimate was incorrect.
// Increment the exponent and don't perform the premultiply needed
// for the first loop iteration.
digitExponent = digitExponent + 1;
}
else
{
// The exponent estimate was correct.
// Multiply larger by the output base to prepare for the first loop iteration.
BigInt_Multiply10( &scaledValue );
BigInt_Multiply10( &scaledMarginLow );
if (pScaledMarginHigh != &scaledMarginLow)
BigInt_Multiply2( pScaledMarginHigh, scaledMarginLow );
}
// Compute the cutoff exponent (the exponent of the final digit to print).
// Default to the maximum size of the output buffer.
tS32 cutoffExponent = digitExponent - bufferSize;
switch(cutoffMode)
{
// print digits until we pass the accuracy margin limits or buffer size
case CutoffMode_Unique:
break;
// print cutoffNumber of digits or until we reach the buffer size
case CutoffMode_TotalLength:
{
tS32 desiredCutoffExponent = digitExponent - (tS32)cutoffNumber;
if (desiredCutoffExponent > cutoffExponent)
cutoffExponent = desiredCutoffExponent;
}
break;
// print cutoffNumber digits past the decimal point or until we reach the buffer size
case CutoffMode_FractionLength:
{
tS32 desiredCutoffExponent = -(tS32)cutoffNumber;
if (desiredCutoffExponent > cutoffExponent)
cutoffExponent = desiredCutoffExponent;
}
break;
}
// Output the exponent of the first digit we will print
*pOutExponent = digitExponent-1;
// In preparation for calling BigInt_DivideWithRemainder_MaxQuotient9(),
// we need to scale up our values such that the highest block of the denominator
// is greater than or equal to 8. We also need to guarantee that the numerator
// can never have a length greater than the denominator after each loop iteration.
// This requires the highest block of the denominator to be less than or equal to
// 429496729 which is the highest number that can be multiplied by 10 without
// overflowing to a new block.
RJ_ASSERT( scale.GetLength() > 0 );
tU32 hiBlock = scale.GetBlock( scale.GetLength() - 1 );
if (hiBlock < 8 || hiBlock > 429496729)
{
// Perform a bit shift on all values to get the highest block of the denominator into
// the range [8,429496729]. We are more likely to make accurate quotient estimations
// in BigInt_DivideWithRemainder_MaxQuotient9() with higher denominator values so
// we shift the denominator to place the highest bit at index 27 of the highest block.
// This is safe because (2^28 - 1) = 268435455 which is less than 429496729. This means
// that all values with a highest bit at index 27 are within range.
tU32 hiBlockLog2 = LogBase2(hiBlock);
RJ_ASSERT(hiBlockLog2 < 3 || hiBlockLog2 > 27);
tU32 shift = (32 + 27 - hiBlockLog2) % 32;
BigInt_ShiftLeft( &scale, shift );
BigInt_ShiftLeft( &scaledValue, shift);
BigInt_ShiftLeft( &scaledMarginLow, shift);
if (pScaledMarginHigh != &scaledMarginLow)
BigInt_Multiply2( pScaledMarginHigh, scaledMarginLow );
}
// These values are used to inspect why the print loop terminated so we can properly
// round the final digit.
tB low; // did the value get within marginLow distance from zero
tB high; // did the value get within marginHigh distance from one
tU32 outputDigit; // current digit being output
if (cutoffMode == CutoffMode_Unique)
{
// For the unique cutoff mode, we will try to print until we have reached a level of
// precision that uniquely distinguishes this value from its neighbors. If we run
// out of space in the output buffer, we terminate early.
for (;;)
{
digitExponent = digitExponent-1;
// divide out the scale to extract the digit
outputDigit = BigInt_DivideWithRemainder_MaxQuotient9(&scaledValue, scale);
RJ_ASSERT( outputDigit < 10 );
// update the high end of the value
tBigInt scaledValueHigh;
BigInt_Add( &scaledValueHigh, scaledValue, *pScaledMarginHigh );
// stop looping if we are far enough away from our neighboring values
// or if we have reached the cutoff digit
low = BigInt_Compare(scaledValue, scaledMarginLow) < 0;
high = BigInt_Compare(scaledValueHigh, scale) > 0;
if (low | high | (digitExponent == cutoffExponent))
break;
// store the output digit
*pCurDigit = (tC8)('0' + outputDigit);
++pCurDigit;
// multiply larger by the output base
BigInt_Multiply10( &scaledValue );
BigInt_Multiply10( &scaledMarginLow );
if (pScaledMarginHigh != &scaledMarginLow)
BigInt_Multiply2( pScaledMarginHigh, scaledMarginLow );
}
}
else
{
// For length based cutoff modes, we will try to print until we
// have exhausted all precision (i.e. all remaining digits are zeros) or
// until we reach the desired cutoff digit.
low = false;
high = false;
for (;;)
{
digitExponent = digitExponent-1;
// divide out the scale to extract the digit
outputDigit = BigInt_DivideWithRemainder_MaxQuotient9(&scaledValue, scale);
RJ_ASSERT( outputDigit < 10 );
if ( scaledValue.IsZero() | (digitExponent == cutoffExponent) )
break;
// store the output digit
*pCurDigit = (tC8)('0' + outputDigit);
++pCurDigit;
// multiply larger by the output base
BigInt_Multiply10(&scaledValue);
}
}
// round off the final digit
// default to rounding down if value got too close to 0
tB roundDown = low;
// if it is legal to round up and down
if (low == high)
{
// round to the closest digit by comparing value with 0.5. To do this we need to convert
// the inequality to large integer values.
// compare( value, 0.5 )
// compare( scale * value, scale * 0.5 )
// compare( 2 * scale * value, scale )
BigInt_Multiply2(&scaledValue);
tS32 compare = BigInt_Compare(scaledValue, scale);
roundDown = compare < 0;
// if we are directly in the middle, round towards the even digit (i.e. IEEE rouding rules)
if (compare == 0)
roundDown = (outputDigit & 1) == 0;
}
// print the rounded digit
if (roundDown)
{
*pCurDigit = (tC8)('0' + outputDigit);
++pCurDigit;
}
else
{
// handle rounding up
if (outputDigit == 9)
{
// find the first non-nine prior digit
for (;;)
{
// if we are at the first digit
if (pCurDigit == pOutBuffer)
{
// output 1 at the next highest exponent
*pCurDigit = '1';
++pCurDigit;
*pOutExponent += 1;
break;
}
--pCurDigit;
if (*pCurDigit != '9')
{
// increment the digit
*pCurDigit += 1;
++pCurDigit;
break;
}
}
}
else
{
// values in the range [0,8] can perform a simple round up
*pCurDigit = (tC8)('0' + outputDigit + 1);
++pCurDigit;
}
}
// return the number of digits output
tU32 outputLen = (tU32)(pCurDigit - pOutBuffer);
RJ_ASSERT(outputLen <= bufferSize);
return outputLen;
}
Formatting Numbers
Next, we will write the code that wraps up the Dragon4 algorithm and outputs formatted strings. Click here to read part 3..
Comments